
 English
EnglishDaten, Informationen, Rauschen und…
vor lauter Wald die Bäume nicht sehen!
Heute hat jeder verstanden, wie wichtig es ist alle Arten von anfallenden Daten, auch in großen Mengen zu sammeln, aufzubereiten und für aktuelle oder zukünftige Auswertungen zu bevorraten. Speicherplatz ist günstig und Daten fallen zu Genüge in jedem Geschäftsprozess an… Aber was dann?
Was tun, um „DRIP“ zu vermeiden?
Wir sehen zunehmend das Problem, dass Handelsunternehmen reich an Daten sind, aber arm an Informationen bleiben. Eine Erfahrung die als DRIP („data rich, information poor„) bekannt ist. Trotz umfänglicher Datensammlungen, bleibt es in vielen Unternehmen schwer echten Nutzen aus diesen zu ziehen.
Intelligente Datenanalyse als Schlüssel zum Erfolg
Professionelle Datenanalysten können zwar gut mit Methoden der künstlichen Intelligenz (KI) umgehen, maschinelles Lernen einsetzen, um Einflüsse und ihre Wirkungen zu erkennen. Das aber stellt nur „die halbe Miete“, denn die fehlende Erfahrung mit Handelsprozessen hat sie nicht die „typischen Fehler“ erfahren lassen, die erst erkennen lassen, wie und welches „Rauschen“ aus verfügbaren Daten zu filtern ist, um tatsächlichen Mehrwert zu gewinnen und diesen umzusetzen…
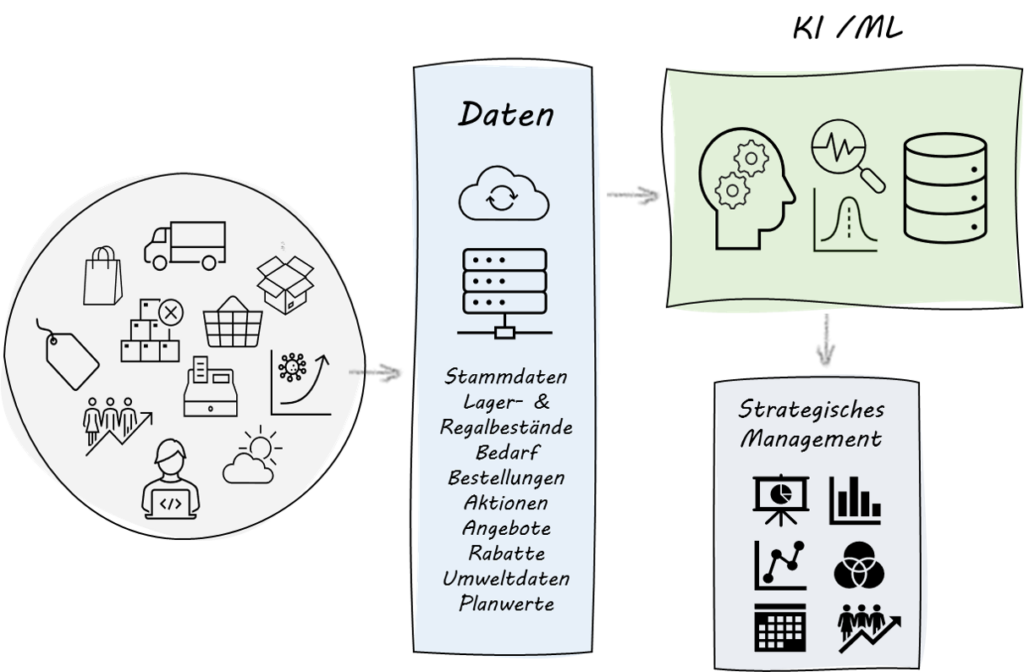
Prognosen sind dabei nur der erste Schritt
Der Fokus im Einsatz neuer Methoden der künstlichen Intelligenz liegt häufig bei den Prognosen. Daten aber, clever gesammelte, vom „Rauschen“ bereinigt und prozessorientiert interpretiert, haben so viel mehr zu bieten.“ Sie erlauben eine bessere Bewertung der Warenbewegung und dem Wareneingang, der Optimierung von Bestellstrategien, bei der Planung und Prognostizierung von Sonderaktionen und auch der Minimierung von manuellem Aufwand. Bereinigte Daten sichern die Automatisierung, bieten strategische Informationen für das Management und helfen Entscheidungen im Vorfeld zu prüfen und besser zu planen, Einflüsse genauer zu simulieren und Ergebnisse zu überwachen.